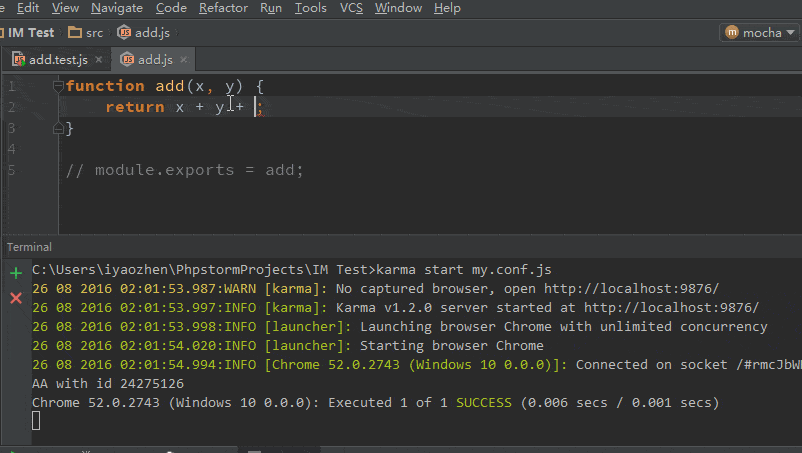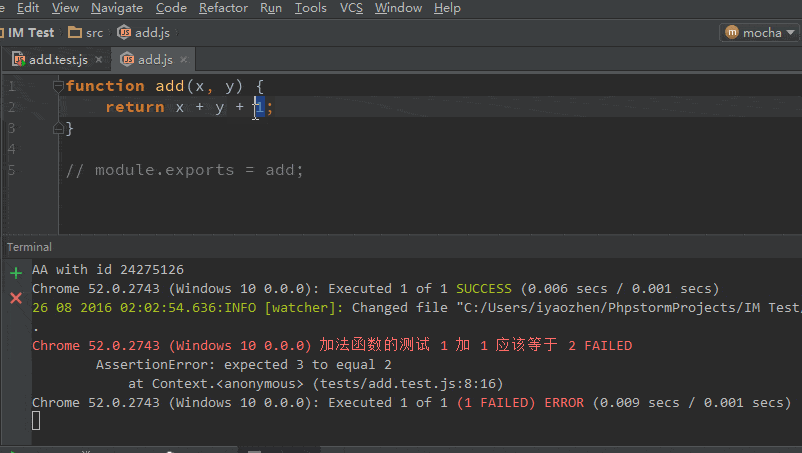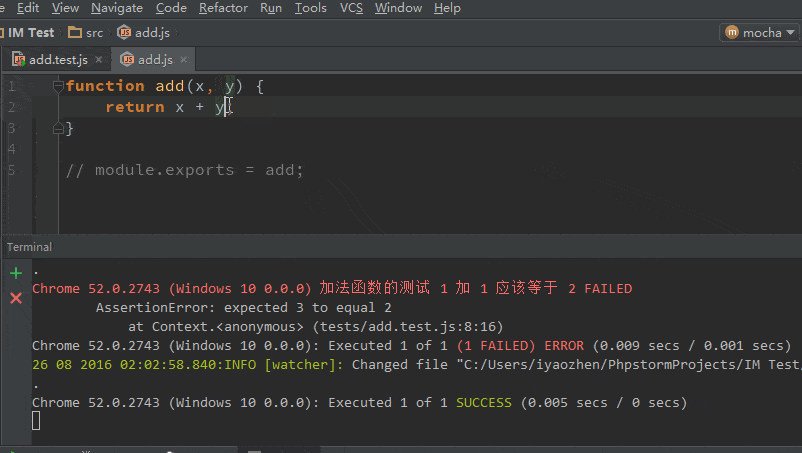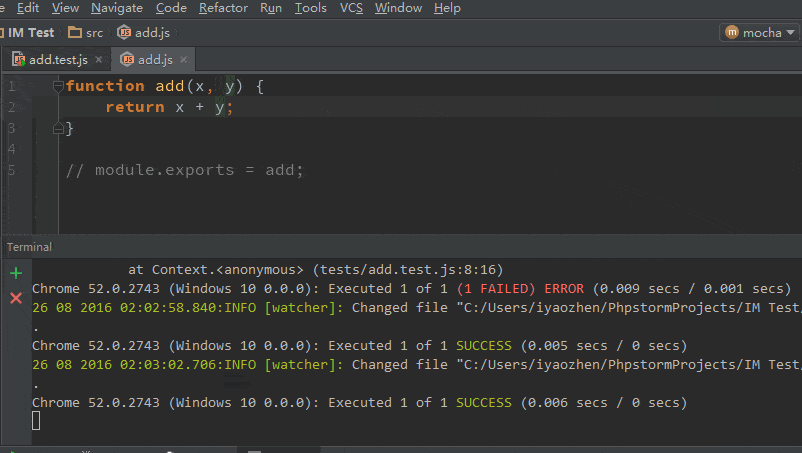
今晚上线了一个新的 web 页面,主要多了一个背景视频功能。但上线后遇到一个问题,HTTPS 下背景视频很大概率不播放。线下测试的时候遇到过类似的问题,是因为 webserver 没有在 mime.types 文件添加video/mp4 mp4 mp4v mpg4浏览器不能识别的原因,但线上确定不是这个原因。
Chrome 抓包发现是视频文件请求 412 了,单独访问这个视频文件也是 412 偶现不能访问,但 http 下却没有这个问题。查了下 412 是连接建立先决条件失败,第一次遇到这个错误码,直接看状态码定义,看不出个所以然。看起来自己一时半会儿解决不了呀,马上把这个问题抛到公司的群里,一会儿得到了几个大神的回复:很大可能是 If-Match 和 ETag 对不上的问题。仔细看了下 412 的请求 headers 部分确实是这个现象。
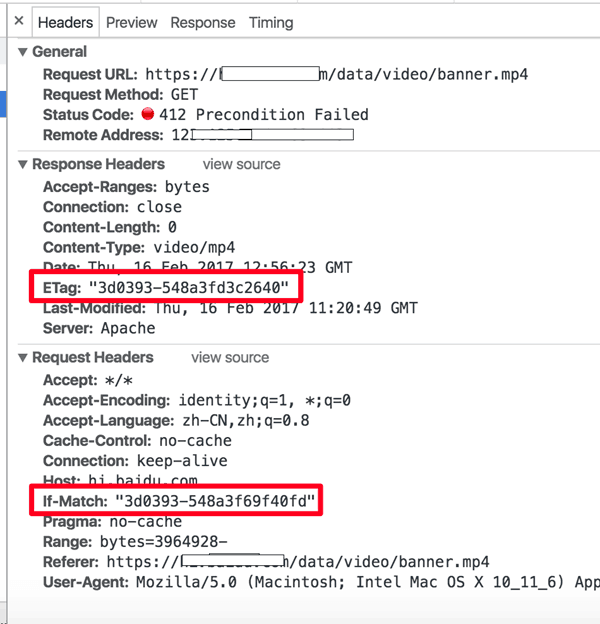
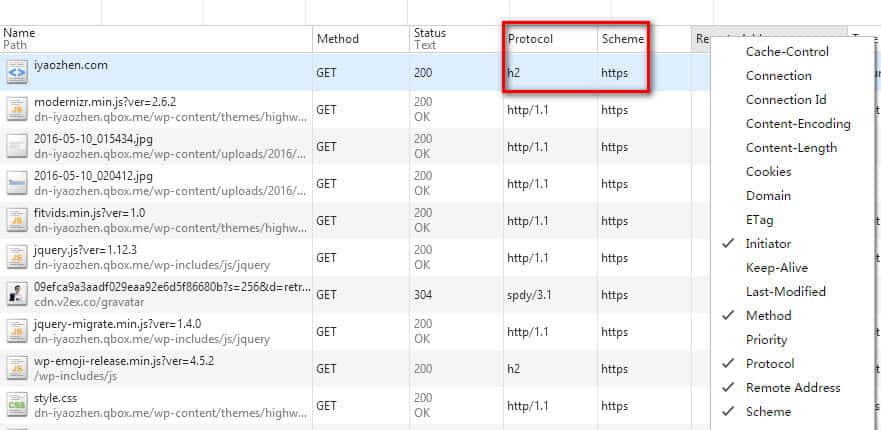
可以看到,Chrome 在加载一个视频的时候是分段加载,当某一个请求 412 的时候会造成整个视频加载失败。群里的璐神给了一些参考资料,里面有一段说明:
在大型多 WEB 集群时,使用 ETag 时有问题,所以有人建议使用 WEB 集群时不要使用 ETag,其实很好解决,因为多服务器时, INode不一样,所以不同的服务器生成的 ETag 不一样,所以用户有可能重复下载(这时 ETag 就会不准),明白了上面的原理和设置后,解决方法也很容易,让 ETag 后面 二个参数,MTime 和 Size 就好了。只要 ETag 的计算没有 INode 参于计算,就会很准了。
觉得这个说得很有道理,决定改一下 Apache 服务器试试。看配置文件的时候发现,http 的配置下有一行 FileETag -INode -MTime Size 的配置,但是 https 下没有,把这一行也加到 https 的配置文件中果然就行了。
虽然问题是解决了,但是感觉还是没有找到根本原因的样子。看了下 Apache 的文档发现 FileETag 默认使用 MTime 和 Size 两个参数,因为集群部署代码时是串行的,且会改变文件的时间(OP 部署系统的锅,中间有一步进行了 cp 操作),所以应该是 MTime 不一样造成了每台服务器上应该是同一个文件的 ETag 不一样,而每个分片请求落在了不同的机器上,造成If-Match和ETag对不上,不是之前猜测的 INode 问题。但感觉还是哪里不对,为什么If-Match和ETag对上了的请求就没问题了,按照理解ETag是用来做缓存的,对不上很正常,web server应该返回完整内容呀。下班回家又仔细想了一下,觉得这个问题应该反过来思考,因为 Chrome 是分段加载视频,需要保证这个视频在加载过程中是没有变动的,这样才有意义,所以需要每次请求都对比 ETag。那么为什么其它浏览器没这个问题了,抓包发现 IE 没有分段下载功能,是当一个文件都加载完成后才播放。FireFox 没有带上 If-Match 的请求头:
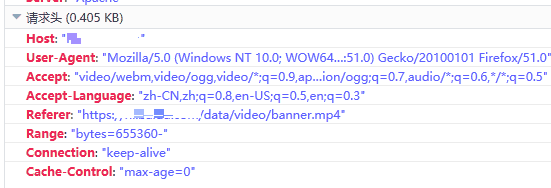
Safari 也没有使用 If-Match 的请求头,因此就 Chrome 下有这个问题。If-Match 的说明也验证了我的猜想:
For GET and HEAD methods, used in combination with an Range header, it can guarantee that the new ranges requested comes from the same resource than the previous one. If it doesn't match, then a 416 (Range Not Satisfiable) response is returned.
当然我这个案例中错误码是 412(通常用作 PUT 方法更新资源出错时),不过这是一个意思,符合预期。
ETag 工作流程和生成算法补充:当客户端第一次向服务器请求资源时,服务器会返回资源并根据资源的一些信息生成 ETag 返回给客户端,客户端不需要了解 ETag 是如何生成的,只需缓存下 ETag 当下次请求时带上(If-None-Match: ETag)。表示如果这个资源的 ETag 和我请求的不一样则返回数据,一样则返回 304。
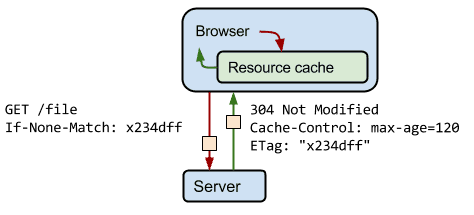
不同个 webServer 生成 ETag 的算法可能不一样,比如上面提到的 Apache 使用的是 INode MTime Size 三个文件属性计算而得:
|
1 2 3 4 5 6 |
$fs = stat($file); sprintf('Etag: "%x-%x-%s"', $fs['ino'], $fs['size'], base_convert(str_pad($fs['mtime'], 16, '0'), 10, 16) ) |

参考资料:
Apache配置Etag详解 https://www.yudouyudou.com/jiaochengheji/wangzhanjianshe/262.html
https://httpd.apache.org/docs/2.4/mod/core.html#fileetag
https://developer.mozilla.org/en-US/docs/Web/HTTP/Status/412
https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/If-Match
https://web.dev/articles/http-cache
https://stackoverflow.com/questions/44937/how-do-you-make-an-etag-that-matches-apache