目录
Filebeat简介
现在 ELK(Elasticsearch、Logstash 和 Kibana)日志分析系统非常火,但相关的介绍忽略了重要的一环:日志采集。虽然 Logstash 也能采集日志,但比较重、资源占用高,显然不适合线上和业务部署,所以一开始搞了个 logstash-forwarder 后来整合为 Filebeat。慢慢还发展成了一个 Beats 系列,支持采集各种各样的元数据。
Filebeat原理
说到实时查看日志,最常用得莫过于 tail -f 命令,基于此可以自己实现一个简单的日志采集工具,https://github.com/iyaozhen/filebeat.py/blob/master/filebeat.py#L237
但这太简陋了,无法保证不丢不重。我们看看 Filebeat 是怎么实现的,官方说明:https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-overview.html
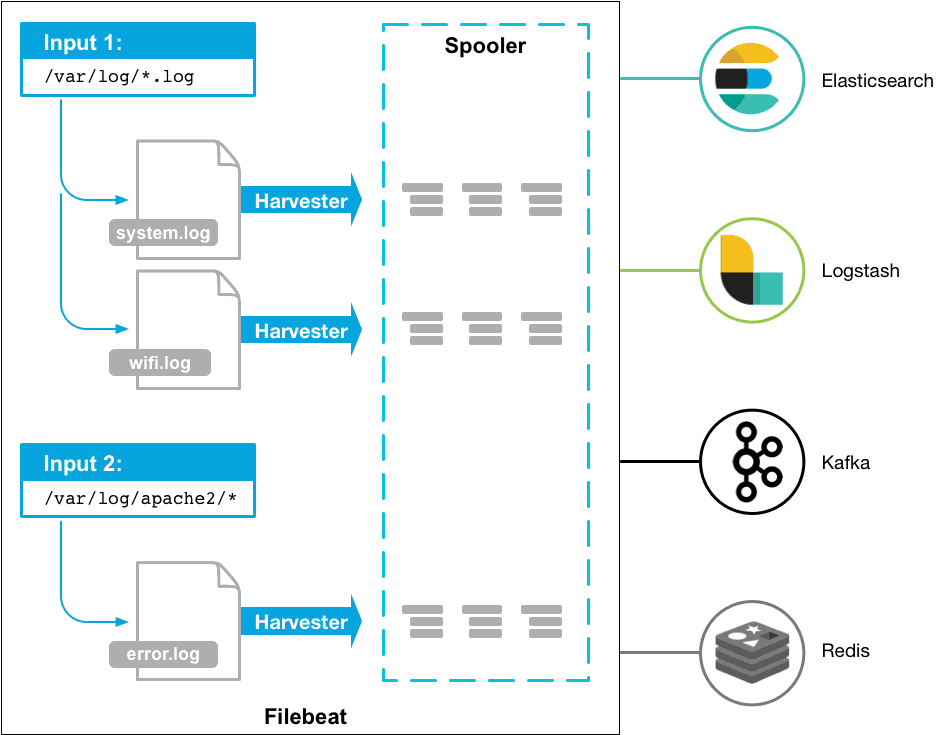
简单来说 Filebeat 有两大部分,inputs 和 harvesters,inputs 负责找文件(类似 find 命令)和管理 harvesters,一个 harvester 则和一个文件一一对应,一行行读然后发送给 output(类似tail -f)。
当然还有很多细节问题,我们结合配置文件一一详解。
Log input配置详解
官方配置说明:https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-input-log.html
先看一个基本例子(下面所述基于7.x版本,6.x版本也基本适用)
|
1 2 3 4 5 6 7 8 9 10 11 |
filebeat.inputs: - type: log paths: - /var/log/system.log - /var/log/wifi.log - type: log paths: - "/var/log/apache2/*" fields: apache: true fields_under_root: true |
inputs 可以配置多块(block),就是相同类型的放一块,这个也很好理解。paths 可以配置多个文件,文件路径和文件名都支持通配。
ignore_older 和 scan_frequency
这就有两个细节问题了,一是路径下的历史文件可能很多,比如配置了按天分割,显然旧文件我们一般是不需要的。二是扫描频率如何控制,通配设置复杂的话频繁扫文件也是很大的开销。
问题一则是通过 ignore_older 参数解决,意思就是多久前的旧文件就不管了。比如设置为 1h,表示文件时间在 1h 之前的日志都不会被 input 模块搜集,直到有新日志产生。
问题二则是通过 scan_frequency 参数控制,表示多久扫描一次是否有新文件产生。比如设置 10s(默认),一个新文件产生 10s 后会被发现,或者一个旧文件(上面 ignore_older)新产生了一行日志 10s 才发现这个文件。有人说我需要实时性,是不是这个值设置的越小越好,其实是错误的,前面我们介绍了 Filebeat 架构,input 模块只是负责发现新文件,新文件是相对已经被 harvester 获取的文件,第一次发现之后就已经在被 harvester 一行行实时读取了,所以这里基本上只影响日志切分时的实时性(这种场景下的短暂延迟是可以接受的)。
close_* 和 clean_*
那么被 harvester 获取的文件就一直拿着不放吗?文件重命名或者被删除后怎么办呢?这里重点介绍这两组配置。
close_* 配置簇
The close_* configuration options are used to close the harvester after a certain criteria or time. Closing the harvester means closing the file handler.
close_inactive,我们都知道打开了文件需要 close,不能占用文件不释放,不然即使 rm 了文件,磁盘空间也不会释放(早期 Filebeat 有这个bug)。这个配置就是说明多久关闭文件,比如一个日志文件,10 分钟都没有读到新的内容就把文件句柄关闭。这里的时间不是取决于文件的最后更新时间,而是 Filebeat 内部记录的时间,上次读到文件和这次尝试读文件的时间差。官方建议设置的时间是比文件产生数据频率高一个数量级(默认5m),比如每秒都有日志产生,这个值就可以设置为 1m。
close_renamed,是否关闭 rename 的文件。这里先介绍下常规的日志切分方案,正常是到周期后把 file.log mv 成 file.log.bak,此时应用进程的文件句柄是指向 file.log.bak 的,新的内容持续在 file.log.bak 中新增,然后给进程发送 kill SIGUSR1 信号,让程序重新打开文件句柄,往 file.log 打日志。这个配置默认是关闭的,意思是文件重命名后,还会继续读取 file.log.bak close_inactive 时间,然后关闭文件,新的 file.log 也会 scan_frequency 时间被发现,开始读取新的内容。如果设置了这个参数,则文件被 rename 就马上关闭文件,这样的话,按前述的日志切分流程,会有数据丢失。但还是建议开启,不然会有文件占用不释放的问题。
close_removed,默认是开启的。意思就是文件被删除后,就关闭文件句柄。这个符合正常场景,一般日志清理程序都是清理,很多天前的日志,这个时间远远大于 ignore_older 和 close_inactive。
close_timeout,默认值是0(不生效)。When this option is enabled, Filebeat gives every harvester a predefined lifetime. 这个配置不常用,个人理解是 close 相关操作的一个延迟时间。比如设置了 close_removed 当文件被删除试,不马上关掉文件句柄,而是继续保持 close_timeout 后关闭。个人没遇到过需求场景
clean_* 配置簇
The clean_* options are used to clean up the state entries in the registry file. 之前也提到过,Filebeat 有一个内部记录了很多文件状态,保存在 data/registry/filebeat/data.json。如果不清理的话这个文件会越来越大,影响效率。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
{ "source": "/xxx/logs/logFile.2019-09-20.log", "offset": 661620031, "timestamp": "2019-09-21T00:04:23.050179808+08:00", "ttl": 10800000000000, "type": "log", "meta": null, "FileStateOS": { "inode": 184559118, "device": 2056 } } |
clean_inactive,多久清理一次注册信息。当然清理的文件信息,肯定是需要保证这个文件已经不活跃了,所以这个值需要大于 ignore_older + scan_frequency。不然的话清理后这个文件又被发现,则会重头开始读取,这样就重了。默认值是0(不开启clean_*相关功能)。
clean_removed,文件被删除后是否清理注册信息,需要和 close_removed 值保持一致,默认也是开启的。一般保持默认就行,极端场景比如掉盘后,磁盘再挂载,会被当做新文件重新读取。这里有个文件重命名的场景,当文件重命名后,也会清理注册信息(在文件读取完成后,不会丢数据)。
简单总结几个时间配置:clean_inactive > ignore_older + scan_frequency > close_inactive
我们这边日志一般按小时分割,推荐配置:
|
1 2 3 4 5 6 7 8 |
tail_files: false scan_frequency: 10s ignore_older: 60m close_inactive: 10m close_renamed: true close_removed: true clean_inactive: 70m clean_removed: true |
其它 tail_files、include_lines、exclude_lines、multiline(多行匹配)等比较简单,查看官方文档即可。
资源限制
Filebeat 设计上来说性能非常好,但也有优化空间,比如在日志非常多机器负载高的时候加重机器负担,建议生产环境上需要对 Filebeat 资源进行限制:
max_procs 最多使用多少核,默认会全部使用,按机器情况限制为1-4核,不太会影响推送效率。
filebeat.registry.flush Filebeat 会记录文件读到了哪里,然后更新到本地文件,方便下次启动的时候继续读取文件。咋一看没有问题,但当日志量特别大的时候,registry 文件会变更特别频繁(默认是 0s,立即写入磁盘),造成非常高的磁盘 IOPS,特别是机械盘,进而影响业务程序。建议设置 10-60s,正常停止的时候会直接写入文件,这个值配置的大也不影响,只是异常退出再启动后,会重复推送这几秒的日志。
Beats central management使用问题
Filebeat 配置功能很强大,而且业务也在变化,这就免不了去更新配置,机器比较多上配置文件很麻烦,所以需要一个集中管理的平台,收费版 X-Pack 带有此功能(Beats central management),虽然是测试版(后来放弃了),但基本能用。如何配置使用就不介绍了,这里说说遇到的几个问题:
1. outputs kafka client close invalid memory address or nil pointer dereference

现象就是运行中 Filebeat 进程就没了,查看源码发现挂在了关闭 kafka 连接的地方,https://github.com/elastic/beats/blob/7.0/libbeat/outputs/kafka/client.go#L108

应该是 c.producer 空指针了(实际是 kafka pipeline 内部竞争机制的问题,导致某些条件下 close 比 connect 先调用),查看更新的代码(7.2)修复了此问题(加了锁和判空):https://github.com/elastic/beats/pull/12453/files

2. Error creating runner from config: Can only start an input when all related states are finished
意思是读取到配置中心的新配置,但当前还有采集任务未完成。这个不会让 filbeat 进程挂掉,只是状态会变成 Error,还是会继续使用之前的配置文件运行。一般会自行恢复(下次再拉取配置文件的时候)。
如果持续出现,且未恢复到 running 状态,就需要考虑,前文所述的 clean_* 配置簇是否正确,及时清理文件注册状态,同时增大拉取配置的间隔(management.period,默认 1m),没必要频繁拉取。
配置自动加载
前面介绍了 Beats central management,看似不错,但实际使用下了,稳定性还是欠佳,不适合生产环境。而且新版官方也放弃了此方案,不过好在也支持了配置动态加载。
|
1 2 3 4 5 |
filebeat.config.inputs: enabled: true path: configs/*.yml reload.enabled: true reload.period: 10s |
具体的 input 配置文件放在 configs 文件夹下,例如:
|
1 2 3 4 |
- type: log paths: - /var/log/messages - /var/log/*.log |
和Docker结合
Filebeat 官方支持 Docker/K8s,但在做私有化部署的时候发现客户的容器管理平台很烂,几乎不支持日志采集,因此需要有一个更简单、普适性更强的方案(选用 Filebeat 部署)。因此我们可以借助上面说的自动加载能力,把 Filebeat 打到基础镜像中,path 配置为固定目录,比如 /home/filebeat/configs/*.yml,然后业务代码制作成新镜像时,把自生业务的 filebeat 配置 COPY 到此目录,这样不依赖与容器管理平台,即使裸 Docker 运行也能有日志采集能力。
结语
这里只介绍了 Log input 其实还有很多其它输入类型,但核心配置都是上面介绍的那些,灵活运用即可。也没介绍 output,因为现在 output 基本上都是 kafka,因为直接到 ES 或 Logstash 扛不住,需要中间一层队列削峰和解耦,通过 Logstash 订阅 kafka,将日志再清洗入 ES 或者转发到其它下游系统,其它数据需求方也可以从此 kafka 分流(基于 consumer group)。
最后希望本文对 Filebeat 的配置详解,能帮助你更好的使用此工具。
参考资料
Common problems https://www.elastic.co/guide/en/beats/filebeat/current/faq.html
")


