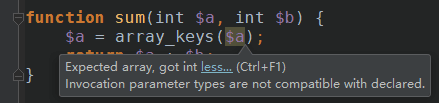
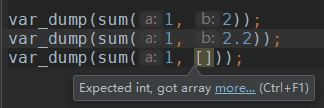
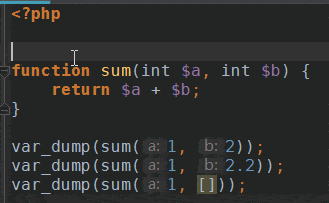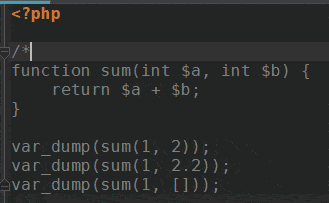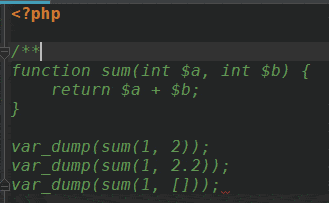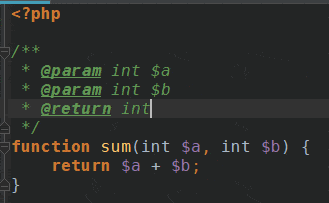
Since release 3.5.0 phpMyAdmin can be configured to remember several things (sorted column $cfg['RememberSorting'], column order, and column visibility from a database table) for browsing tables. Without configuring the storage, these features still can be used, but the values will disappear after you logout.
看来是是环境问题(PHP 5.4)了,回过头来看那句报错,发现用户名好像被截断了(应该是xxx_user),是不是显示的问题,随便改一个用户名试试,同样报错,用户名却没有截断。这时又想了想是不是 MySQL 的版本太高(5.7.10)了。找了个 MySQL 5.5 的环境,创建相同的用户却发现报错了:String 'xxx_user' is too long for user name (should be no longer than 16)。查询 MySQL 文档发现:MySQL user names can be up to 32 characters long (16 characters before MySQL 5.7.8). https://dev.mysql.com/doc/refman/5.7/en/user-names.html
这样看来应该是老版 PHP 的 mysqli 扩展内部限定了用户名的长度,但新版的 MySQL 却可以创建更长的用户名了。知道原因了就很好办了,创建一个短用户名 OK 了。其实也是阴差阳错,因为新库是多应用共有,所以用户名创建的比较长。_(┐「ε:)_