Filebeat简介
现在 ELK(Elasticsearch、Logstash 和 Kibana)日志分析系统非常火,但相关的介绍忽略了重要的一环:日志采集。虽然 Logstash 也能采集日志,但比较重、资源占用高,显然不适合线上和业务部署,所以一开始搞了个 logstash-forwarder 后来整合为 Filebeat。慢慢还发展成了一个 Beats 系列,支持采集各种各样的元数据。
Filebeat原理
说到实时查看日志,最常用得莫过于 tail -f 命令,基于此可以自己实现一个简单的日志采集工具,https://github.com/iyaozhen/filebeat.py/blob/master/filebeat.py#L237
但这太简陋了,无法保证不丢不重。我们看看 Filebeat 是怎么实现的,官方说明:https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-overview.html
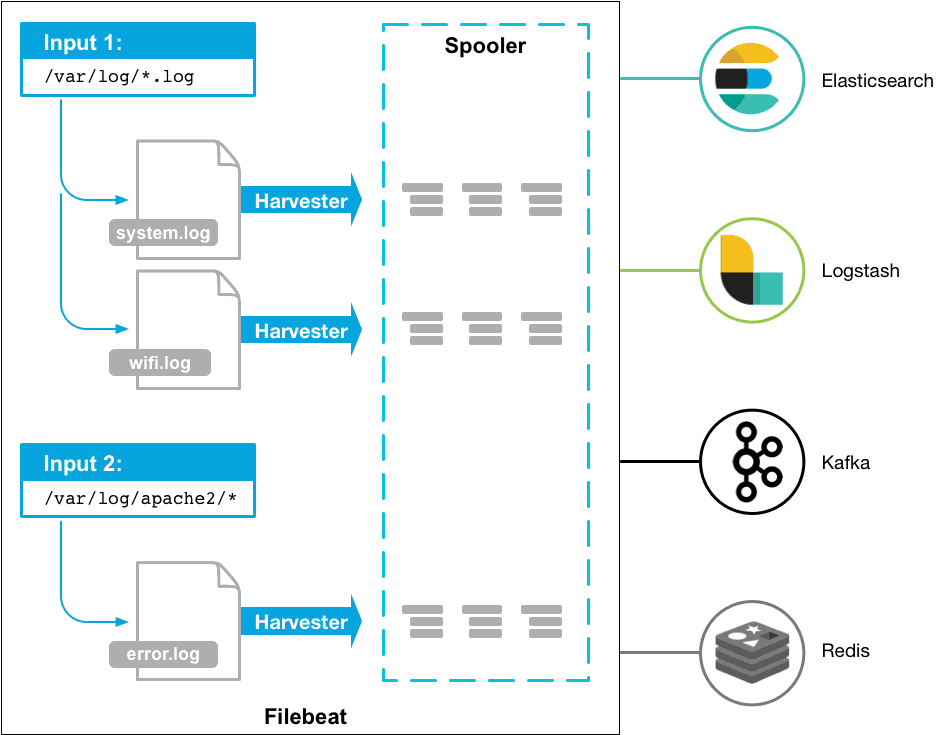
简单来说 Filebeat 有两大部分,inputs 和 harvesters,inputs 负责找文件(类似 find 命令)和管理 harvesters,一个 harvester 则和一个文件一一对应,一行行读然后发送给 output(类似tail -f)。
当然还有很多细节问题,我们结合配置文件一一详解。
Log input配置详解
官方配置说明:https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-input-log.html
先看一个基本例子(下面所述基于7.x版本,6.x版本也基本适用)
|
1 2 3 4 5 6 7 8 9 10 11 |
filebeat.inputs: - type: log paths: - /var/log/system.log - /var/log/wifi.log - type: log paths: - "/var/log/apache2/*" fields: apache: true fields_under_root: true |
inputs 可以配置多块(block),就是相同类型的放一块,这个也很好理解。paths 可以配置多个文件,文件路径和文件名都支持通配。
ignore_older 和 scan_frequency
这就有两个细节问题了,一是路径下的历史文件可能很多,比如配置了按天分割,显然旧文件我们一般是不需要的。二是扫描频率如何控制,通配设置复杂的话频繁扫文件也是很大的开销。
问题一则是通过 ignore_older 参数解决,意思就是多久前的旧文件就不管了。比如设置为 1h,表示文件时间在 1h 之前的日志都不会被 input 模块搜集,直到有新日志产生。
问题二则是通过 scan_frequency 参数控制,表示多久扫描一次是否有新文件产生。比如设置 10s(默认),一个新文件产生 10s 后会被发现,或者一个旧文件(上面 ignore_older)新产生了一行日志 10s 才发现这个文件。有人说我需要实时性,是不是这个值设置的越小越好,其实是错误的,前面我们介绍了 Filebeat 架构,input 模块只是负责发现新文件,新文件是相对已经被 harvester 获取的文件,第一次发现之后就已经在被 harvester 一行行实时读取了,所以这里基本上只影响日志切分时的实时性(这种场景下的短暂延迟是可以接受的)。
close_* 和 clean_*
那么被 harvester 获取的文件就一直拿着不放吗?文件重命名或者被删除后怎么办呢?这里重点介绍这两组配置。 Continue Reading...