我们一般使用 RSA 的时候,都是公钥加密,私钥解密。

因为从设计上来说公钥大家都有,私钥只有一方有,这样更安全,但实际来说也可以私钥加密,公钥解密。openssl有对应实现,但Python没有,项目中需要用到,所以还得尝试实现下。
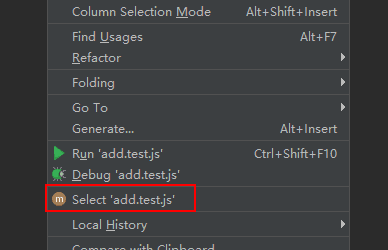
Python的rsa库虽然没有提供公钥解密但提供了公钥verification方法,里面有使用公钥解密signature的代码,可以依样画葫芦。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
keylength = common.byte_size(pub_key.n) encrypted = transform.bytes2int(signature) decrypted = core.decrypt_int(encrypted, pub_key.e, pub_key.n) clearsig = transform.int2bytes(decrypted, keylength) def decrypt_int(cyphertext: int, dkey: int, n: int) -> int: """Decrypts a cypher text using the decryption key 'dkey', working modulo n""" assert_int(cyphertext, "cyphertext") assert_int(dkey, "dkey") assert_int(n, "n") message = pow(cyphertext, dkey, n) return message |
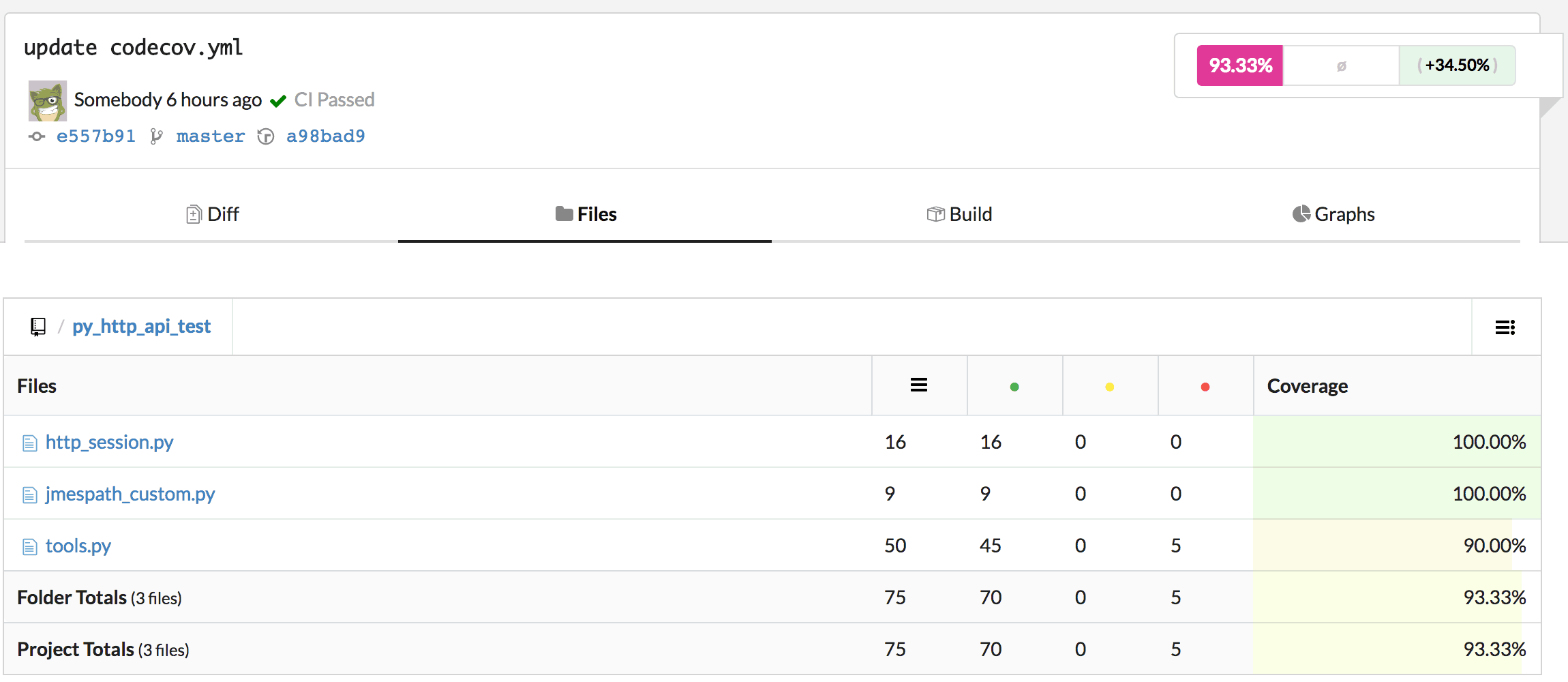
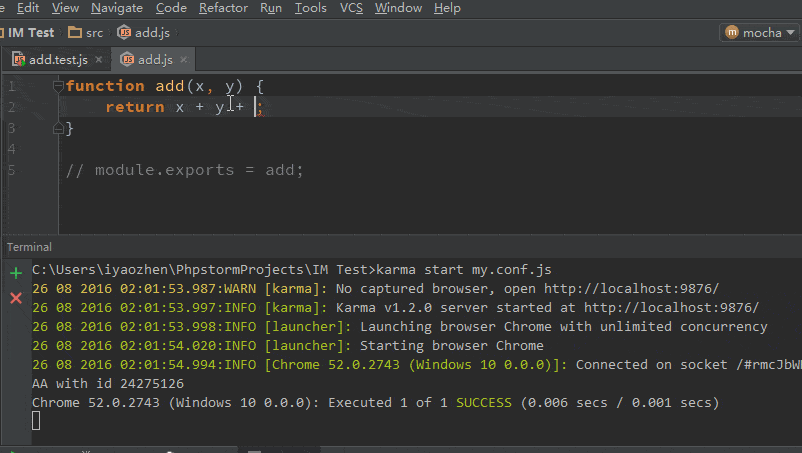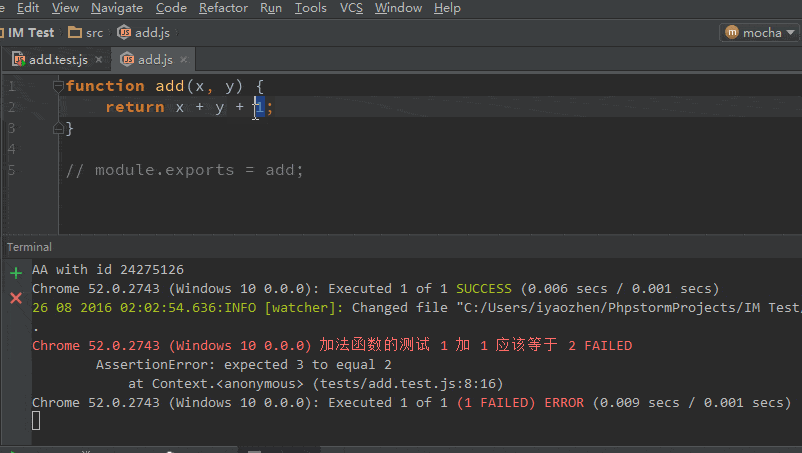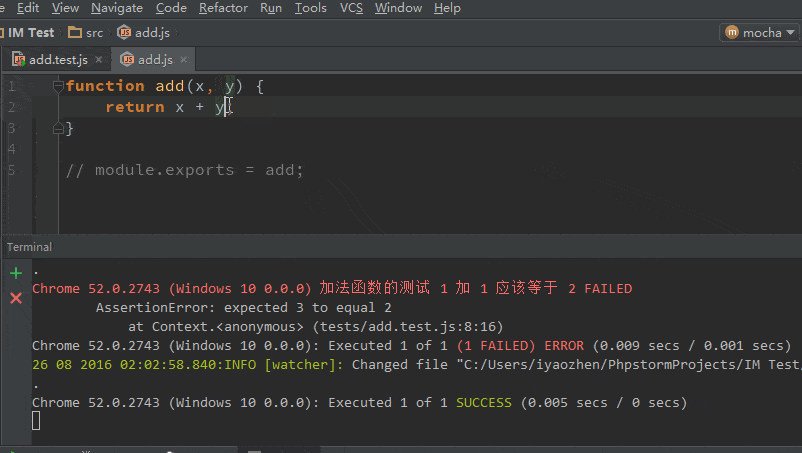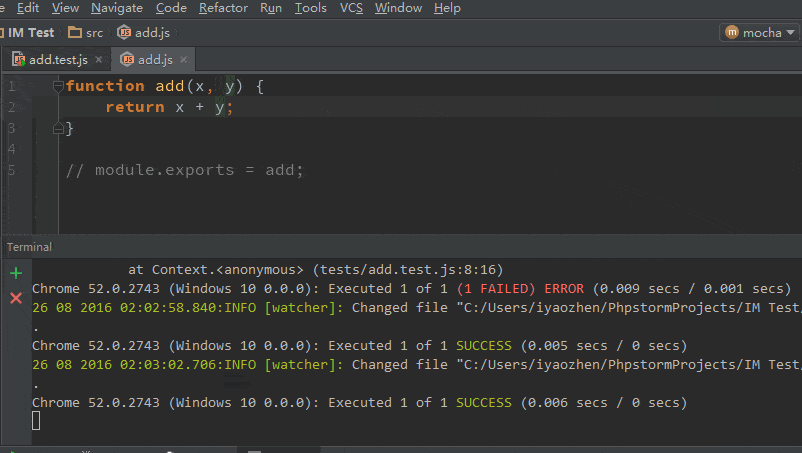
同时也支持了长文本解密(分段)。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
import Crypto.PublicKey.RSA from rsa import transform, core, common, PublicKey def rsa_public_decrypt(cls, pub_key: bytes, data: bytes) -> bytes: pub_key = Crypto.PublicKey.RSA.import_key(pub_key) block_size = common.byte_size(pub_key.n) def decrypt(data): # 解密 cypher_text = transform.bytes2int(data) decrypted = core.decrypt_int(cypher_text, pub_key.e, pub_key.n) clear_text = transform.int2bytes(decrypted, block_size) try: # Find the 00 separator between the padding and the message sep_idx = clear_text.index(b'\x00', 2) except ValueError: raise RuntimeError('rsa_public_decrypt failed, clear_text=%s' % clear_text) clear_text = clear_text[sep_idx + 1:] return clear_text # 分段解密 total_length = len(data) default_length = 128 res = [] offset = 0 while offset < total_length: res.append(decrypt(data[offset:offset + default_length])) offset += default_length return b''.join(res) |
不过在实际使用过程中,发现rsa_public_decrypt特别慢,起初认为是rsa算法的问题,因为rsa设计上也不是用来加解密较长的文本。一番定位发现是PublicKey.load_pkcs1比较慢,在我Mac上需要3061000 ns,当然一般来说不需要每次都导入公钥,但我实际场景有点特殊,每次公钥都不一样,这个导入操作需要再优化下。
一番定位发现是底层返回public key对象时有个consistency_check参数写死了True,表示会校验n和e是否互为质数,但n和key的位数有关,一般特别大,一般求GCD(最大公约数)使用辗转相除法,即非常耗CPU,这也是Python的弱势,所以比较慢。
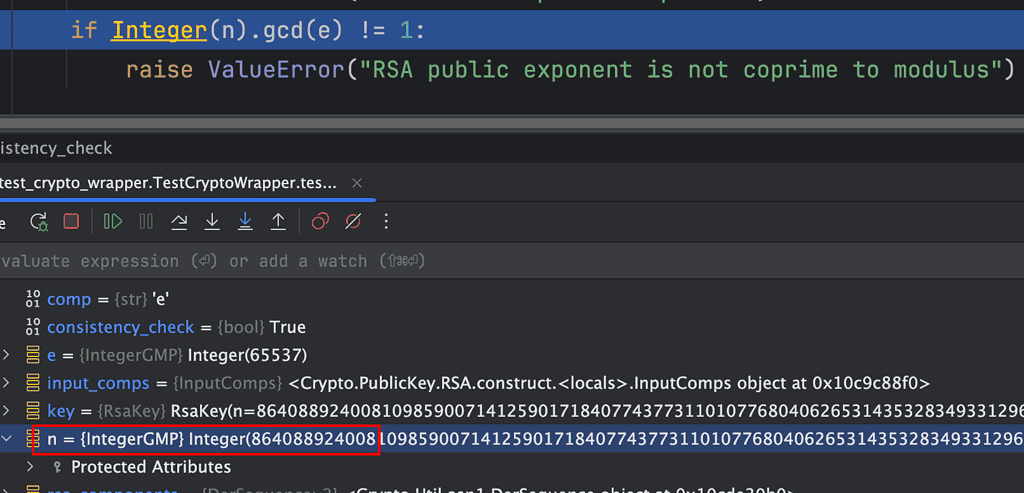
但我的场景可以确定rsa key是合法的,因此可以不校验。在我本地测试仅需290000 ns,提高了一个数量级。
|
1 2 3 |
def _import_pkcs1_public(cls, pub_key: bytes): der = DerSequence().decode(pub_key, nr_elements=2, only_ints_expected=True) return RSA.construct(der, consistency_check=False) |
后记:
这个问题是早些年解决的,那时候还没有ChatGPT,不断搜资料,也搞了好久。不过这个问题ChatGPT现在还是不能直接给出答案,会使用rsa.decrypt(encrypted_message, public_key),但相关库并不支持这样。如果你了解 RSA 原理的话,稍加引导,它最终还是能给出一个非常接近的答案,调一调其实就能用了,不得不感叹科技的进步。